반응형
해당 게시글은 국민대학교 이경용 교수님의
클라우드 컴퓨팅 수업 내용을
바탕으로 작성하였습니다.
고가용성 (High Availability) 이란?
- 서비스를 운용하는 사람이 관리를 하지 않아도 서비스가 동작하지 않은 시간 최소화하여 사용자에게 예측된 성능을 제공해줄 수 있는 척도
- 구축 시 추가 cost 발생

구현 요소들
- Fault tolerance : 실패 내성 (문제가 발생해도 사용자에게 영향을 전파하지 않는 능력)
- Scalability : 확장성 (시스템 설계를 바꾸지 않고도 증가하는 요청을 처리할 수 있는 능력)
사용자 보유 데이터 센터와 클라우드에서의 고가용성 & 여러 Region들
- 사용자 보유 데이터 센터
- 많은 경비 소요 (하드웨어 구매, 서버룸 구축 등)
- 중요한 일부 서비스에 대해서만 고가용성 확보
- 클라우드
- 여러 대 서버
- 여러 Region 활용
- 가용성이 높아짐
- 하지만 더 많은 경비가 소요되고, 시스템이 복잡해질 수 있음.
- 한 Region 내 여러 AZ 활용
- 서비스에 내재된 Fault tolerance (fully-managed Service) 활용.
- 서비스 자체에서 Cloud Vendor가 알아서 지원해줌!
반드시 여러 Region에서 서비스를 해야하는 것이 아니면, 하나의 Region에서 서비스를 시작하되, 최소한 여러 AZ는 사용하는 것이 이상적임.
AWS Managed 고가용성 서비스 - AWS Load Balancer
- 여러 AZ 사이에 배포된 EC2 인스턴스로 부하 상태 및 동작 상태를 고려하여 사용자 요청을 분배해주는 역할.
- EC2 인스턴스 health check -> 정상 동작하지 않는 인스턴스 탐지
- 여러 지역은 전달 불가능 (Route53 이용)

Application Load Balancer
- OSI 7계층 중 Application 단에서 동작함 -> 컨텐츠 기반 라우팅
- HTTP/HTTPS 요청의 헤더, 메서드, 경로 등을 분석하고, 적절한 Target Group으로 요청을 전달
- IP 주소 + 포트 번호 + L7 정보(헤더, URI 경로 등)를 확인하여 라우팅
- IP 주소가 변동되기 때문에 Client에서 Access 할 ELB의 DNS Name을 이용
- L7단을 지원하기 때문에 SSL 적용이 가능
ex>
- HTTP Endpoint에 따른 라우팅.
- 경로 기반 라우팅(Path-based Routing)을 지원
- 다른 경로의 서비스들이 다른 호스트에 의해 제공 가능
- www.example.com/admin => admin 서버
- www.example.com/customer => 소비자 서버
Network Load Balancer
- OSI 7계층 중 Transport 단에서 동작 (IP:Port) -> TCP/UDP 기반 라우팅
- TCP/UDP 헤더 정보를 확인하고 요청을 Target Group으로 전달
- IP + Port를 기준으로 트래픽을 라우팅
- 할당한 Elastic IP를 Static IP로 사용이 가능하여 DNS Name과 IP 주소 모두 사용이 가능합니다.
- NLB는 SSL 적용이 인프라 단에서 불가능하여 애플리케이션에서 따로 적용해 주어야 합니다.
ex>
같은 응용 서비스를 제공하는 여러 인스턴스에 요청을 임의로 분배
- 클라이언트가 특정 포트를 통해 요청을 보내면, NLB는 이를 Target Group의 한 인스턴스에 전달
Gateway Load Balancer
- Inbound Traffic에 대한 단일 진입점 제공 -> 보안서비스 구축 가능하게 해줌
- 실제로 독립적인 서비스로 런칭함. (AGLB)
ALB에 고정 IP 적용
ALB는 기본적으로 IP가 변경되기 때문에 고정 IP를 가질 수 있는 NLB를 앞에 둠으로서 적용 가능

AWS Load Balancer Sticky Session
Sticky 세션은 사용자의 요청 또는 세션이 특정 인스턴스에 바인드 되어 다른 인스턴스로 향하지 못하게 해주는 기능
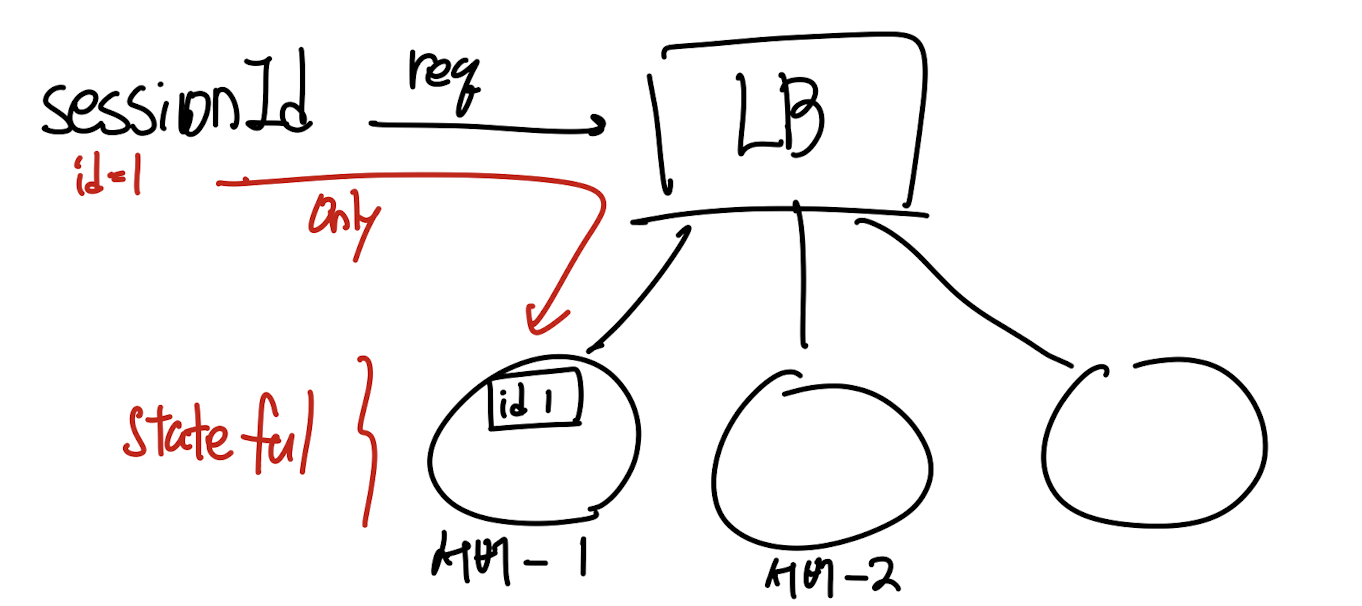
- Sticky 세션이 동작하지 않는 것 (default) -> 가장 작은 부하를 가진 서버로 요청 전달
- 세션 정보를 유지하고 있어야 할 때 사용하면 좋음 (stateful)
- 쿠키를 통해서 로드밸런서 서비스가 특정 인스턴스로 요청 전달
단점
- stateful한 특성으로 인해 확장성이 제한됨.
- 불공평한 부하 처리 부담 발생 가능
단점 극복 방안
- 세션 정보 -> 빠른 읽기를 지원하는 분산 서비스 사용
- 분산 캐시 저장소, NoSQL 서비스 사용 -> 서버에 session을 두지 않고 cache에 저장하는 것.
Load Balancer와 TLS/SSL Termination
HTTP 통신 중 중요 정보를 전송 시 클라이언트 단에서 암호화 -> 서버단에서 복호화 처리
- TLS/SSL Termination
- 암호화되어 도착한 사용자 데이터를 복호화 하여 plain text 형식의 데이터로 변환하는 과정.
- EC2 환경에서 Termination 가능 단계
- Load Balancer : ELB가 복호화한 후 VPC 내 Private Network를 통해 EC2로 전달
- EC2 : 암호화가 된 채로 전달된 후 EC2에서 직접 복호화
정리
- Application Load Balancer
- 반드시 TLS/SSL Termination 필요!
- 복호화 후 header 정보를 확인하여 요청을 라우팅하기 때문
- 따라서 ELB에서 복호화 해야 함.
- Network Load Balancer
- end-to-end encryption이 필수여서 EC2 단에서 복호화 하는 경우
- HTTPS 사용 불가
- EC2 단에서 복호화 해야 함.
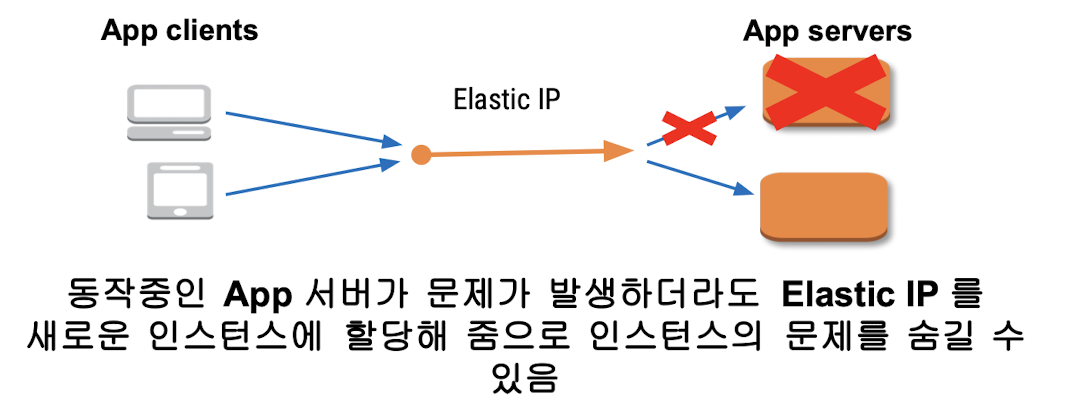
AWS Elastic IP
EC2 인스턴스를 생성 및 시작 시 Cloud Vender Public IPv4 Pool에서 임의의 IP를 할당해줌.
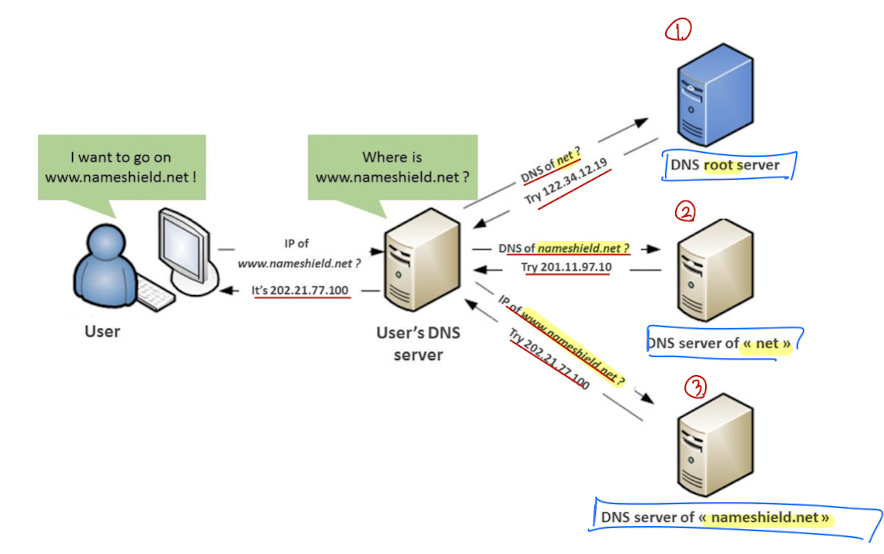
Amazon Route 53
- Region 사이에서의 부하 분산
- Fully-managed DNS 서비스
- DNS Query는 UDP 53 port에서 이루어짐
- 도메인 등록
- DNS 관리
- 가용성 모니터링(Network health check)
- 트래픽 관리(Route policy 등)
특징
- 안정성
- 여러 지역에 백업 시스템 구동
- 빠른 응답속도
- 전세계에서 서비스가 배포되고 서비스 되고 있음.
- 새로운 변화에 대한 빠른 배포 가능
- 손쉬운 사용
- 다양한 Resolve 기법 지원
Route 53 DNS Resolve 라우팅 기법
- Simple Routing
- 하나의 서버만 있는 경우 해당 서버의 IP 주소로만 Resolve
- Weighted Round Robin
- 여러 대의 서버가 있는 경우 각 서버에 가중치를 부여하여 가중치 값에 기반해 IP Resolve 작업 실행
- A/B 테스팅에도 활용 가능
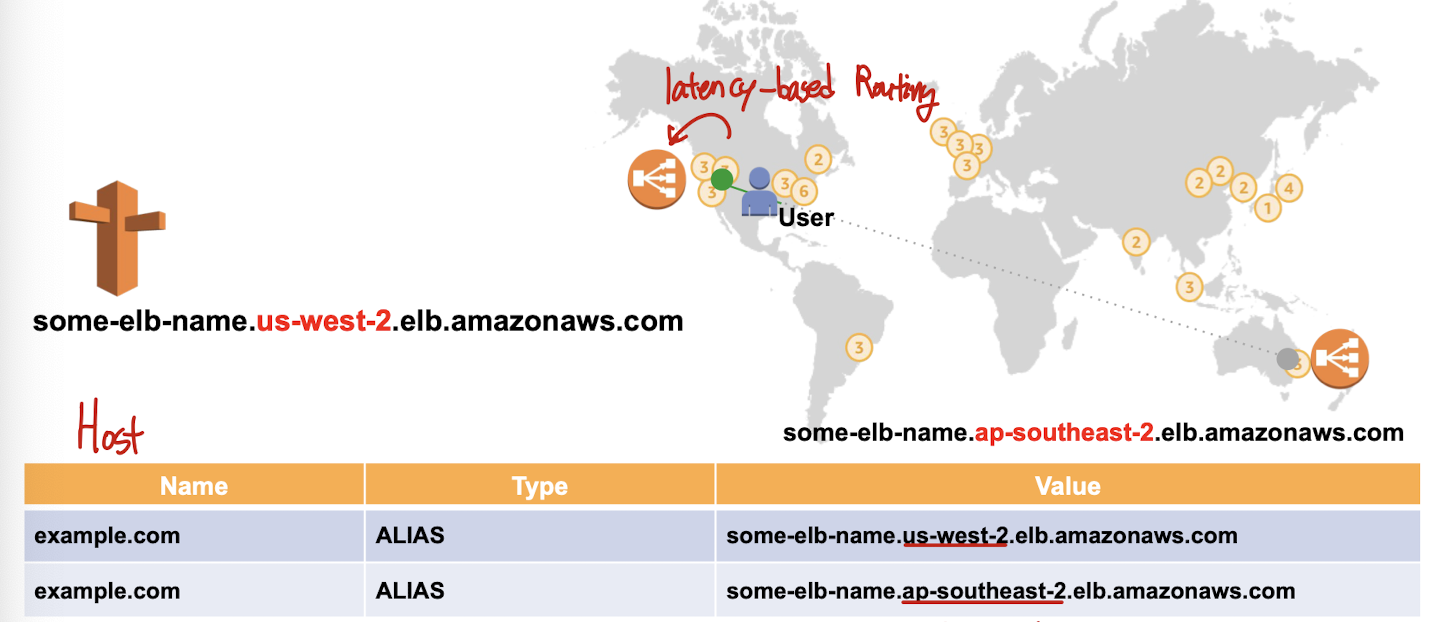
- Latency-based Routing
- 글로벌에 위치한 사용자를 접근이 가장 빠른 서버로 resolve
- Health check and DNS Failover
- 마스터 서버에 문제 발생 시 미리 등록된 백업 서버로 resolve
- Primary-Secondary Routing
- Geolocation Routing
- 특정 나라, 대륙, 지역의 서버만 resolve
Multi-Region 배포
Primary - Secondary 배포
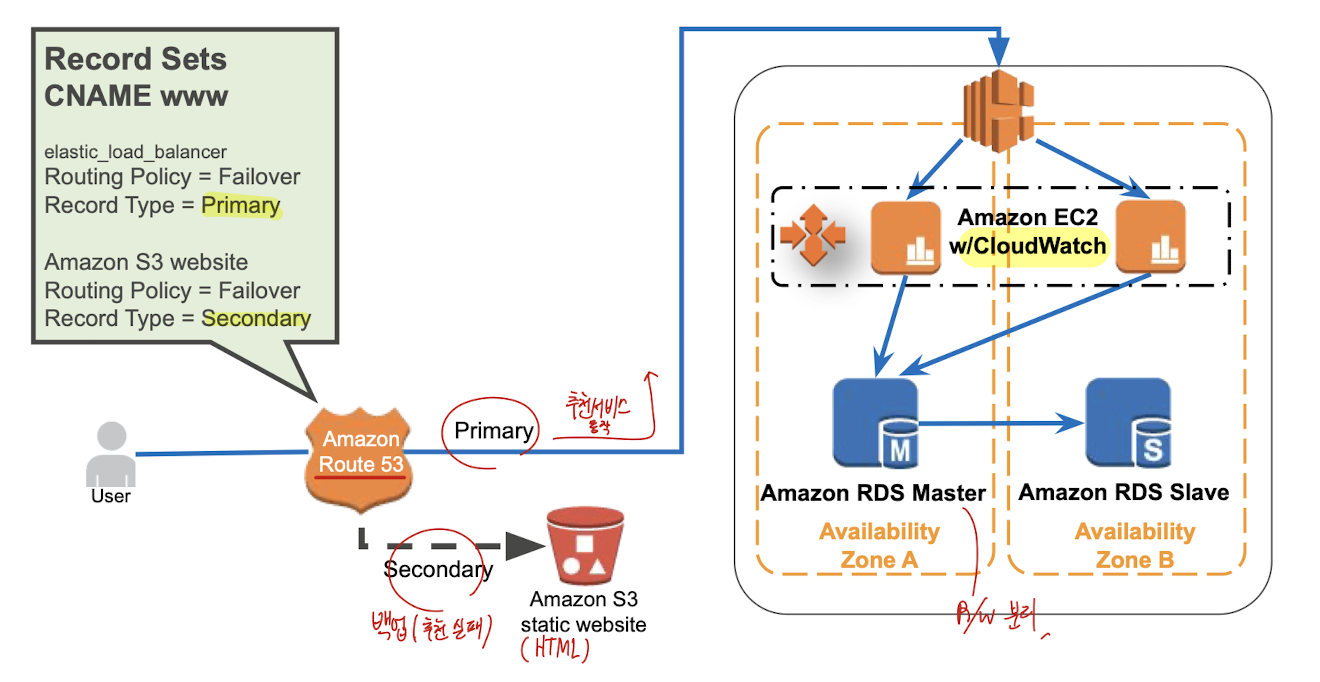
Routing 정책을 Failover resolve를 사용하여 Route 53을 통해 서비스를 호출
Route 53에서 EC2 인스턴스로 라우팅하되, 서비스 응답이 없는 경우 미리 S3에 백업해둔 정적 웹사이트 호스팅
- chaos engineering
- 일부 트래픽에게 실패 시나리오를 주입하여 모니터링하는 기법
확장성 (Scalability) 이란?
사용자의 요청량이 변화함에 따라 이를 처리할 수 있도록 하는 것.
시스템의 확장성 확보 방안
- 수직적 확장 (Scale up / down) : 인스턴스의 하드웨어 스펙 변경
- 수평적 확장 (Scale in / out) : 인스턴스 개수 변화
시스템 확장이 필요한 시기 -> 서비스 컴퓨팅 자원 활용량, 서비스 상태에 따라 판단
Amazon CloudWatch
- 인스턴스의 상태를 관찰하여 실시간으로 정보 제공, 통계 및 알람 제공
- 여러 클라우드 서비스들이 상태 정보를 보내줌.
- 설정된 기준에 따라 Auto Scaling을 가능하게 해줌
- Metric : CPU 이용률, Response Time, Error Rate 등

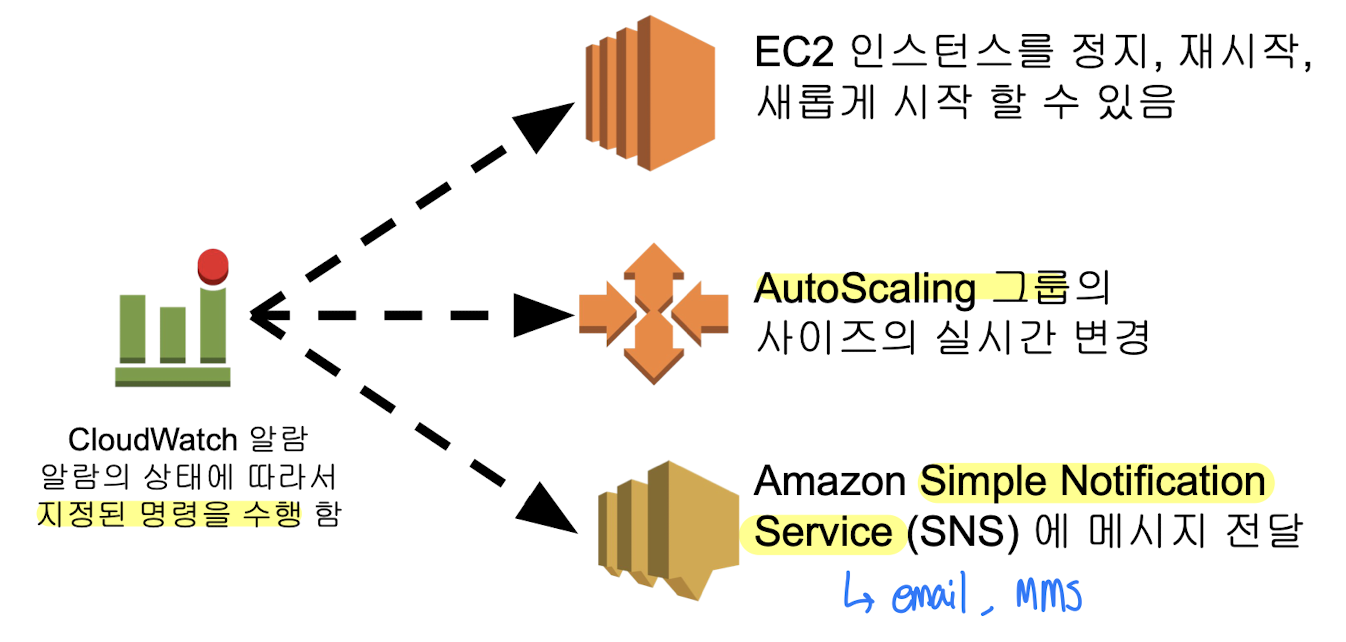
CloudWatch 알람을 이용한 Actions
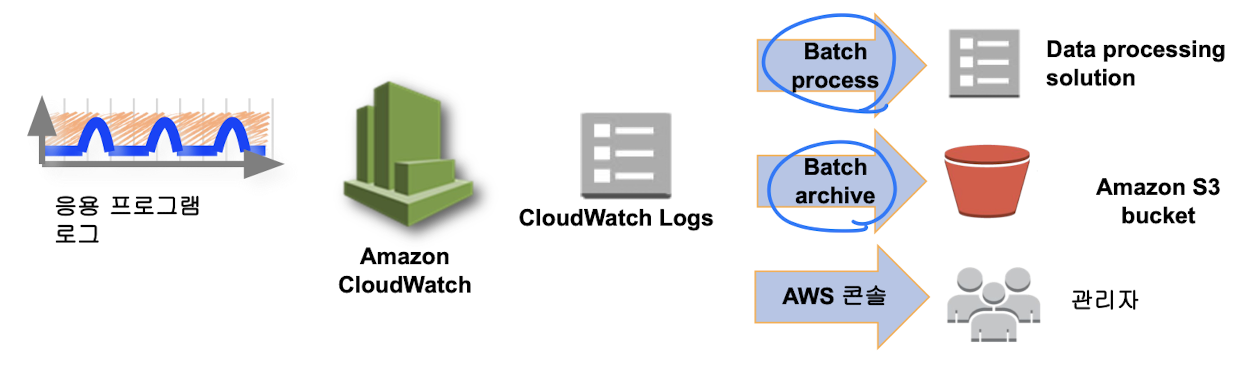
CloudWatch Logs를 활용한 로그 수집
- 실시간 읽기 -> AWS Console
- Batch Processing -> S3에 추가 저장 가능
- 실시간 스트림 처리 -> Amazon Kinesis(스트림 프로세싱 시스템)
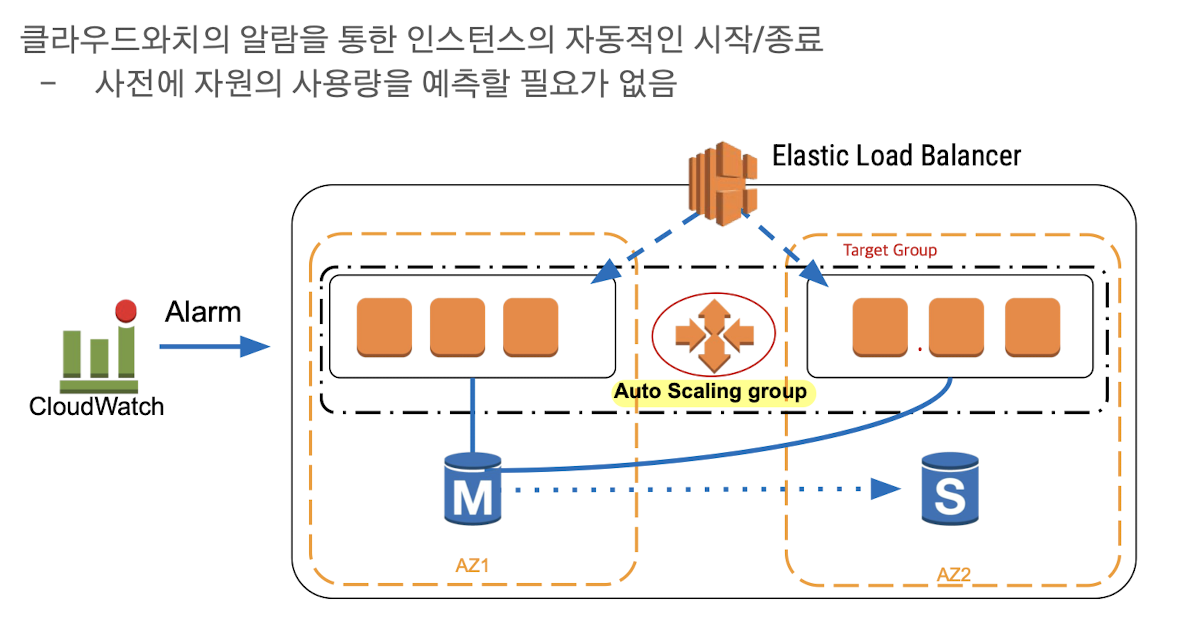
AWS Auto Scaling
- 특정 조건을 만족하는 경우, EC2 인스턴스를 자동으로 시작/종료하게 해줌.
- Auto Scaling에서 시작/정지된 인스턴스는 LB에 자동으로 반영
- 여러 AZ에 걸쳐서 인스턴스를 시작할 수 있음
- 사용자 지정 메트릭을 활용한 scale-in/out 여부 결정
- ex> CPU 사용량이 80% 이상일 때 서버 추가
- 인스턴스들은 초기에 등록된 AZ에 고루 분배됨.
- Metric 값을 구간으로 분리 후 구간 값에 따라 인스턴스 조절 가능
- 평균 CPU 사용률이 80~100%이면 인스턴스 2대 추가, 60~80%이면 1대 추가, 20% 미만이면 1대 감소
설정 방법
- Auto Scaling Group : 자원의 스케일링을 자동으로 하고자 하는 인스턴스 그룹
- Minimum & Maximum, Desired 인스턴스 개수 설정 가능
사용 예제
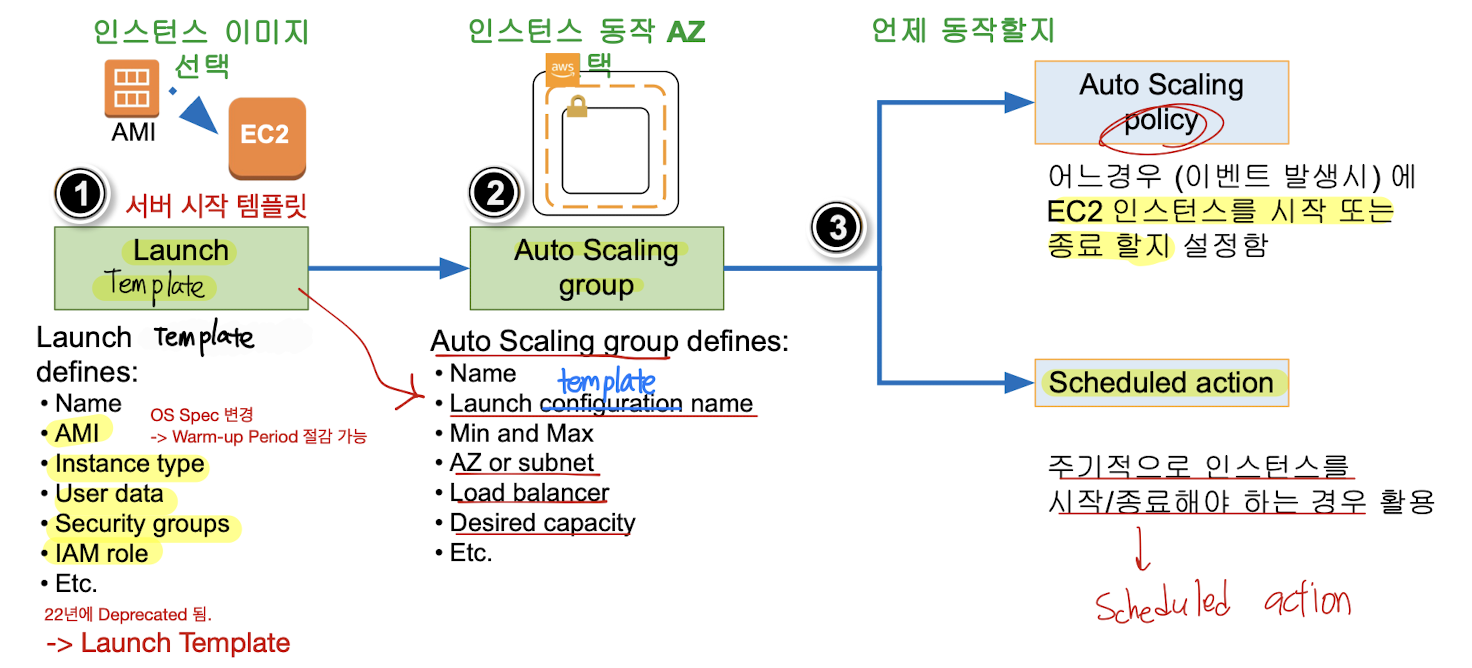
동작 차례
- Launch Template을 활용하여 EC2 인스턴스 설정
- AMI, Instance type, User Data 등 설정 가능
- Auto Scaling Group 설정 (인스턴스 동작 AZ 선택)
- Max, Min, Desired 인스턴스 수
- AZ or Subnet 설정
- 로드밸런서 설정
- 언제 동작할 지 설정 가능
- Auto Scaling Policy : 이벤트에 따른 인스턴스의 시작/종료
- Scheduled Action : 주기적인 인스턴스의 시작/종료
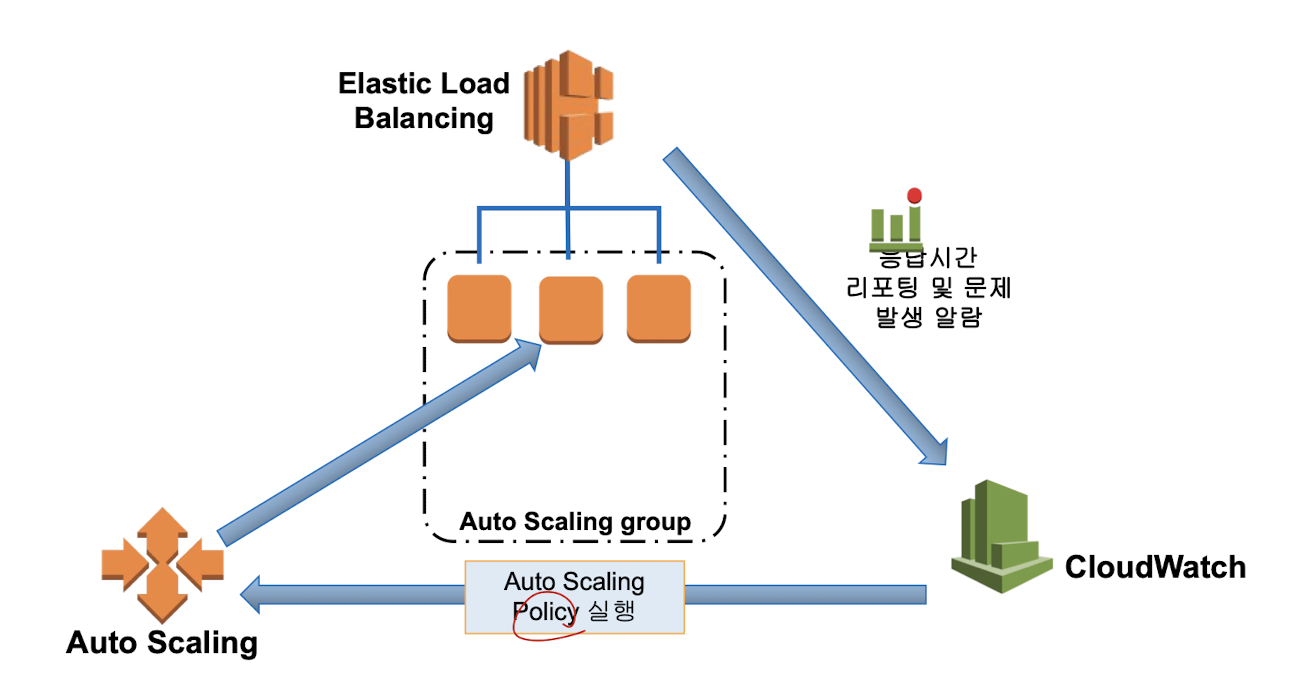
CloudWatch, Elastic Load Balancer, Auto Scaling 사용 예제
Auto Scaling 그룹에서 인스턴스 개수 확인
Maximum, Minimum, Desired 개수 (이상적으로 동작해야 함 -> 로드가 작을 때 최소 인스턴스 개수만)
- 이상적인 Minimum 개수는?
- 각 AZ마다 하나의 인스턴스가 항상 동작해야 한다면 희망 AZ 개수로 설정
- 이상적인 Maximum 개수는?
- 컴퓨팅 리소스 고려
Warm up Period (Server Booting Period)
- 인스턴스 시작 후 준비되기까지 시간이 소요되기에, 새로운 알람이 발생하더라도 시작중인 인스턴스는 동작중인 것으로 판단함.
- 동작중이지 않다고 판단한다면 Auto Scaling으로 인해 계속 EC2가 생성될 것이기 때문.
- Container 사용으로 Cost time 절감 가능
반응형
'Infra & Cloud > Cloud Computing' 카테고리의 다른 글
| [Cloud Computing] Cloud Deployment Automation (1) | 2024.12.06 |
|---|---|
| [Cloud Computing] Serverless Computing (2) | 2024.12.06 |
| [Cloud Computing] Container (2) | 2024.12.06 |
| [Cloud Computing] 2. 클라우드 Basic Service (2) | 2024.11.26 |
| [Cloud Computing] 1. Distribute System (0) | 2024.11.25 |